Figure 1.
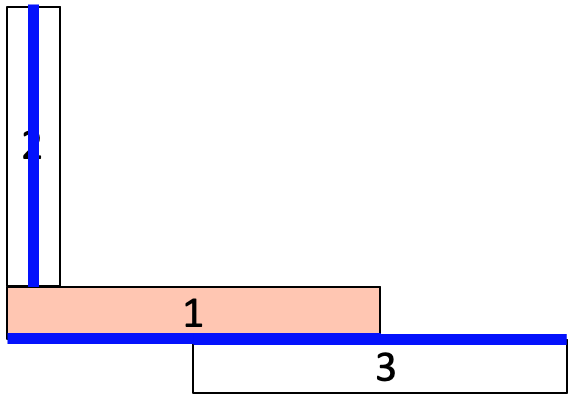
Figure 2.
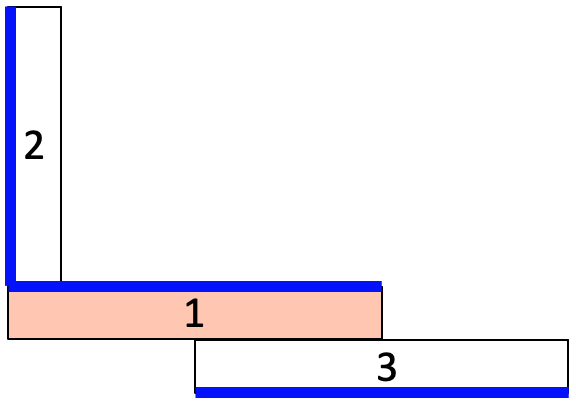
Figure 3.
Cubit 16.10 User Documentation
The Reduce Thin Volumes RL command, similar to the Reduce Thin Volumes Auto simplifies a 3D thin volume into a connected set of sheet bodies. The reduce thin volume commands are frequently used with the intention of generating shell finite elements. In contrast to the auto option, the RL option uses machine learning methods to build a persistent knowledge base to improve its choice of reduce operations. If an assembly has not yet been learned, the method may initially predict a relatively poor solution. As the RL method is run, it builds training data, effectively learning the most suitable reduce solutions for a given configuration of thin volumes. In general, the more diverse problems encountered, the better the outcomes of the RL predictions.
|
Figure 1. |
Figure 2. |
Figure 3. |
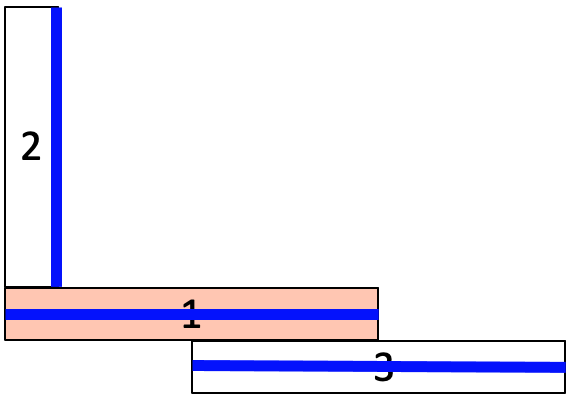
When generating a shell model of a 3D set of thin volumes, the user often must navigate many tools to reduce the volumes and then establish connections. The sequence of commands to build such a model, for anything other than a trivial case, can become unwieldy. Figures 1-3 show one such example where multiple different solutions can be generated for this simple idealized model of the thin volumes. It should be apparent that some solutions may be acceptable, while others are not. The RL tool assists in developing a knowledge base of assembly states and how best to resolve them when encountered.
The RL option can be used to generate a sequence of Cubit commands, which can be exported to a journal file. The user can then validate the result, edit and annotate the journal for archival purposes. The commands generated for reduction will be of the form reduce thin copy or reduce thin midsurface. Note that these commands will perform similar geometric operations to the surface copy and midsurface commands, but will also keep track of thickness and loft; attributes necessary for building a full representation for shell finite element analysis. The resulting sheet bodies will also automatically generate blocks with these attributes and will maintain their association to their original 3D parent geometry.
Reduce Volume <volume ids> Thin RL [Number Iterations <value>] [Initialize Random [<value>]] [Stopping Criteria <value>] [Learning Interval <value>] [Journal Result <string>] [Delete] [Preview]
Similar to the Reduce Thin Auto, to use the Reduce Thin RL command, for best results, the 3D thin volumes should be touching so that if the user imprinted and merged them, they would be connected at merged surfaces. This may involve using checking for gaps and overlaps and resolving prior to using this tool. Some cleanup and defeaturing of the volumes may also be necessary, such as removing chamfers, rounds or other small features that may not be relevant to the final FEA model.
Predict Mode: This mode is normally used when sufficient training data has been established. By setting the argument Number Iterations = 1, the RL method will build the sequence of reduce commands based on predictions made from the existing training data.
Learning Mode: This is normally used when working with a new assembly that may be significantly different than previous models encountered. The user will typically run the RL methods for multiple iterations (Number Iterations > 1), allowing the method to gather information about the state space of the assembly. Depending on the complexity of the assembly, this may take anywhere from a few minutes to several hours to gather sufficient data. At each iteration, a single average reward value is computed and displayed at the command line that represents the completeness of the resulting solution. This value is a heuristic measurement of how well the resulting sheet bodies connect as well as other factors including potential introduction of small curves and narrow surfaces.
To operate in learning mode, RL will use various measures to determine when to terminate learning:
User Influenced Learning: The RL tool provides an ideal method for efficiently establishing a lot of training data in a short amount of time. The learning, however is built on internal predefined heuristics that generally apply to most assembly states. The user can over-ride these preferences by adding their own training data. The most convenient way to do that is through the Cubit Geometry Power Tool, using the Thin Volumes diagnostic. This diagnostic will display the current predicted confidence value for a given reduce command in the solution window. This can be influenced by the user by using the maximize or minimize confidence right-click options. These options are also available from the Cubit command line using the Learn series of commands.
Number Iterations <value>: Maximum number of RL iterations to perform before termination. Default is 100.
Initialize Random {<value>}: Used to initialize the state to random reduce solutions. Normally the state is initialized by predicting the best solution based on the current training data. Random initialization can be used for maximum exploration of the state space, and is most useful for models that have not been seen before. It can also be used to experiment with known solutions to see if alternative solutions can be derived. The options <value> is a seed that can be used to guide the internal random number generator.
For maximum exploration of the state space in learning mode, the Initialize Random may also used. Normally, the starting point for the RL method will be a prediction based on the current knowledge base (training data). The Initialize Random options, ignores any current
Stopping Criteria <value>: A value between zero and one. The RL method terminates if the average reward meets or exceed this value. Default value is 0.999.
Learning Interval <value>: Integer value that indicates how often to update the machine learning model. For example, a learning interval of 5 will update the training model with information it has learned at every fifth RL iteration. Following the update, the state rewards will be reinitialized based on predictions from the ML model to begin the next iteration. Default for learning interval is 100. If the default is used, normally the ML model is only updated after the final iteration.
Journal Result "<string>": If a filename is provided using this option, a journal file with that name will be written to the current working directory with the resulting sequence of commands from the best RL iteration. The resulting journal file will be annotated with comments indicating reward values and success or failure of connections.
Delete: Parent volumes will be deleted after the sheet bodies have been generated. This is generally not recommended as the association between 3D solid thin volumes and their resulting child sheet body(s) is maintained behind the scenes in Cubit. Visualization and management of sheet data, such as block attributes is maintained through this association, as well as the Export Shell Data command.
Preview: If the preview option is used, the final best solution will not be executed, but rather a graphical preview of the result will be displayed. The preview will also include visual cues for connections that have been maintained and those that do not. In addition, if the journal result is used, the journal file will also be produced. This option is often used to preview and validate the result, prior to running the resulting journal once the solution is established as acceptable.